

Kodon
- 4976
- 320
- Marianna Czarnecki
Kodon to triplet nukleotydowy, który koduje aminokwasy w kodzie genetycznym Co to jest kodon?
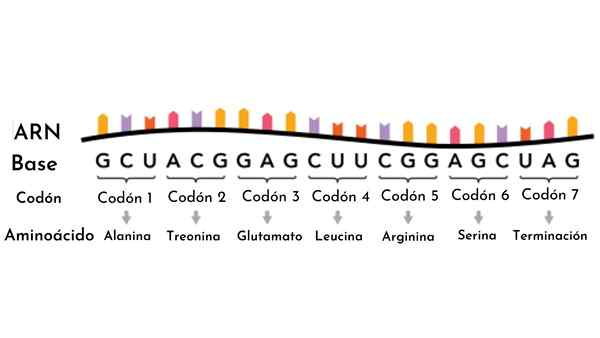
A Kodon Jest to każda z 64 możliwych kombinacji trzech nukleotydów, na podstawie czterech, które tworzą kwasy nukleinowe. To znaczy z kombinacji czterech nukleotydów, budowanych jest bloki trzech „liter” lub trojaczek.
Są to deoksyrybonukleotydy z zasadami adeniny, guaniny, timiny i cytozyny w DNA. W RNA są one rybonukleotydami z zasadami adeniny, guaniny, uracylu i cytozyny.
Pojęcie kodonu stosuje się tylko do genów, które kodują dla białek. Wiadomość zakodowana w DNA zostanie odczytana w trzech blokach do przetworzenia informacji komunikatora.
Kodon w skrócie jest podstawową jednostką kodowania dla przetłumaczonych genów.
Kodony i aminokwasy
Jeśli dla każdej pozycji w trzech literach mamy cztery możliwości, produkt 4 x 4 x 4 zapewnia nam 64 możliwe kombinacje. Każdy z tych kodonów odpowiada konkretnemu aminokwasowi, z wyjątkiem trzech, które funkcjonują jako kodony odczytu.
Konwersja skodyfikowanego przesłania z zasadami azotu w kwas nukleinowy z aminokwasami w peptydie nazywa się translacją. Cząsteczka, która mobilizuje wiadomość z DNA do miejsca tłumaczenia, nazywa się RNA Messenger RNA.
Triplet Messenger RNA to kodon, którego tłumaczenie zostanie przeprowadzone w rybosomach. Małe cząsteczki adaptera, które zmieniają język nukleotydowy na język aminokwasów w rybosomach, to transfer RNA.
Wiadomość, posłańcy i tłumaczenie
Wiadomość kodująca białko składa się z liniowego układu nukleotydowego, który jest wielokrotnością trzech. Wiadomość jest przenoszona przez RNA, którą nazywamy Messenger (RNM).
Może ci służyć: dihibrydyzmW organizmach komórkowych wszystkie RNA powstają przez transkrypcję genu zakodowanego w odpowiednim DNA. Oznacza to, że geny kodujące białka są napisane w DNA w języku DNA.

Nie oznacza to jednak, że ta zasada trzech surowych w DNA jest spełniona. Po przepisaniu z DNA wiadomość jest teraz napisana w języku RNA.
RNM składa się z cząsteczki z komunikatem genowym, otoczonym po obu stronach przez regiony niekodujące. Niektóre modyfikacje post-transcriptal, takie jak na przykład splicing, pozwalają na wygenerowanie wiadomości, która spełnia trzy reguły.
Jeśli ta zasada trzech nie wydawała się spełnić w DNA, splicing jest przywracany.
RNM jest transportowany do miejsca, w którym mieszkają rybosomy, a tutaj komunikator kieruje tłumaczeniem wiadomości na język białka.
W najprostszym przypadku białko (lub peptyd) będzie miało wiele aminokwasów równych jednej trzeciej liter wiadomości bez trzech z nich. To znaczy równa liczbie kodonów posłańca oprócz zakończenia.
Wiadomość genetyczna
Genetyczne przesłanie genu, który kodyfikuje białka zwykle zaczyna się od kodonu, który tłumaczy się jako metoda aminokwasowa (Codón Aug, w RNA).
Następnie charakterystyczna liczba kodonów kontynuuje określoną długość liniową i sekwencję, a kończy w kodonie terminowym. Kodon zakończenia może być jednym z kodonów opalowych (UGA), bursztyn (UAG) lub OCRE (UAA).
Nie ma to odpowiednika w języku aminokwasowym, a zatem, ani odpowiadającego RNA transferu.
Może ci służyć: dziedziczenie holenderskie: cechy, funkcje genów, degeneracjaJednak w niektórych organizmach kodon UGA umożliwia włączenie zmodyfikowanej selenocysteiny aminokwasowej. W innych kodon UAG umożliwia włączenie pirorolisiny aminokwasowej.
RNA komunikatora jest złożone z rybosomami, a inicjacja translacji umożliwia włączenie początkowej metody. Jeśli proces się powiedzie, białko będzie wydłużające się (wydłużanie) w zakresie, w jakim każdy ARNT przekazuje odpowiedni aminokwas prowadzony przez posłańca.
Aby osiągnąć kodon terminowy, włączenie aminokwasów zatrzymuje się, tłumaczenie kończy się i zsyntetyzowany peptyd jest uwalniany.
Kodony i antykodony
Chociaż jest to uproszczenie znacznie bardziej złożonego procesu, interakcja kodon-Aantodon popiera hipotezę translacji przez komplementarność.
Zgodnie z tym dla każdego kodonu w posłańcu interakcja z konkretnym arntem będzie podyktowana komplementarnością podstawami antykodón.
Antikodon jest sekwencją trzech nukleotydów (tryplet) obecnych w okrągłej podstawie typowego arnta. Każdy konkretny arnt może być załadowany określonym aminokwasem, który zawsze będzie taki sam.
W ten sposób, gdy rozpoznawany jest antykodon, Wysłannik wskazuje na rybosom, że aminokwas, który ARNT przenosi, dla którego jest uzupełniający się w tym fragmencie.
ARNT działa zatem jako adapter, który umożliwia weryfikację tłumaczenia przeprowadzonego przez rybosom. Ten adapter, w trzech literowych etapach odczytu kodonu, umożliwia liniowe włączenie aminokwasów, które ostatecznie stanowi przetłumaczone przesłanie.
Degeneracja kodu genetycznego
Korespondencja kodonu: aminokwas jest znany w biologii jako kod genetyczny. Ten kod zawiera również trzy kodony zakończenia tłumaczenia.
Może ci służyć: co to jest apomorphy? (Z przykładami)Istnieje 20 niezbędnych aminokwasów, ale z kolei dostępnych jest 64 kodony do konwersji. Jeśli wyeliminujemy trzy kodony zakończenia, nadal mamy 61 do kodowania aminokwasów.
Metionina jest skodyfikowana tylko przez kodon AUR, który rozpoczyna kodon, ale także tego konkretnego aminokwasu w dowolnym miejscu wiadomości (gen).
To prowadzi nas do 19 aminokwasów kodowanych przez pozostałe 60 kodonów. Wiele aminokwasów jest kodowanych przez pojedynczy kodon. Istnieją jednak inne aminokwasy, które są kodowane przez więcej niż jeden kodon. Ten brak związku między kodonem a aminokwasem jest tym, co nazywamy degeneracją kodu genetycznego.
Organelle
Wreszcie kod genetyczny jest częściowo uniwersalny. W eukariotach istnieją inne organelle (ewolucyjnie pochodne bakterii), w których weryfikowana jest inna translacja niż weryfikowana w cytoplazmie.
Te organelle z własnym genomem (i tłumaczenie) to chloroplasty i mitochondria. Genetyczne kody chloroplastów, mitochondriów, eukariotów i bakteryjnych nukleoidów nie są dokładnie identyczne.
Jednak w każdej grupie jest to uniwersalne. Na przykład gen rośliny, który klon i tłumaczy na komórkę zwierzęcy, spowoduje powstanie peptydu o tej samej liniowej sekwencji aminokwasów, które powinny zostać przetłumaczone na roślinę pochodzenia.
Bibliografia
- Brooker, r. J. Genetyka: analiza i zasady. McGraw-Hill Higher, Education, Nowy Jork.
- Griffiths, a. J. F., Wessler, r., Carroll, s. B., Doebley, J. Wprowadzenie do analizy genetycznej. Nowy Jork.
- Koonin, e. V., Novozhilov, a. S. Pochodzenie i ewolucja uniwersalnego kodu genetycznego. Coroczny przegląd genetyki.